 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Simulation for Policy Learning in Physical Human-Robot Interaction
Apr 09, 2026Developing autonomous physical human-robot interaction (pHRI) systems is limited by the scarcity of large-scale training data to learn robust robot behaviors for real-world applications. In this paper, we introduce a zero-shot "text2sim2real" generative simulation framework that automatically synthesizes diverse pHRI scenarios from high-level natural-language prompts. Leveraging Large Language Models (LLMs) and Vision-Language Models (VLMs), our pipeline procedurally generates soft-body human models, scene layouts, and robot motion trajectories for assistive tasks. We utilize this framework to autonomously collect large-scale synthetic demonstration datasets and then train vision-based imitation learning policies operating on segmented point clouds. We evaluate our approach through a user study on two physically assistive tasks: scratching and bathing. Our learned policies successfully achieve zero-shot sim-to-real transfer, attaining success rates exceeding 80% and demonstrating resilience to unscripted human motion. Overall, we introduce the first generative simulation pipeline for pHRI applications, automating simulation environment synthesis, data collection, and policy learning. Additional information may be found on our project website: https://rchi-lab.github.io/gen_phri/
Control Without Control: Defining Implicit Interaction Paradigms for Autonomous Assistive Robots
Mar 30, 2026Assistive robotic systems have shown growing potential to improve the quality of life of those with disabilities. As researchers explore the automation of various caregiving tasks, considerations for how the technology can still preserve the user's sense of control become paramount to ensuring that robotic systems are aligned with fundamental user needs and motivations. In this work, we present two previously developed systems as design cases through which to explore an interaction paradigm that we call implicit control, where the behavior of an autonomous robot is modified based on users' natural behavioral cues, instead of some direct input. Our selected design cases, unlike systems in past work, specifically probe users' perception of the interaction. We find, from a new thematic analysis of qualitative feedback on both cases, that designing for effective implicit control enables both a reduction in perceived workload and the preservation of the users' sense of control through the system's intuitiveness and responsiveness, contextual awareness, and ability to adapt to preferences. We further derive a set of core guidelines for designers in deciding when and how to apply implicit interaction paradigms for their assistive applications.
Dexterous Manipulation Policies from RGB Human Videos via 4D Hand-Object Trajectory Reconstruction
Feb 09, 2026Multi-finger robotic hand manipulation and grasping are challenging due to the high-dimensional action space and the difficulty of acquiring large-scale training data. Existing approaches largely rely on human teleoperation with wearable devices or specialized sensing equipment to capture hand-object interactions, which limits scalability. In this work, we propose VIDEOMANIP, a device-free framework that learns dexterous manipulation directly from RGB human videos. Leveraging recent advances in computer vision, VIDEOMANIP reconstructs explicit 4D robot-object trajectories from monocular videos by estimating human hand poses, object meshes, and retargets the reconstructed human motions to robotic hands for manipulation learning. To make the reconstructed robot data suitable for dexterous manipulation training, we introduce hand-object contact optimization with interaction-centric grasp modeling, as well as a demonstration synthesis strategy that generates diverse training trajectories from a single video, enabling generalizable policy learning without additional robot demonstrations. In simulation, the learned grasping model achieves a 70.25% success rate across 20 diverse objects using the Inspire Hand. In the real world, manipulation policies trained from RGB videos achieve an average 62.86% success rate across seven tasks using the LEAP Hand, outperforming retargeting-based methods by 15.87%. Project videos are available at videomanip.github.io.
Bimanual High-Density EMG Control for In-Home Mobile Manipulation by a User with Quadriplegia
Feb 02, 2026Mobile manipulators in the home can enable people with cervical spinal cord injury (cSCI) to perform daily physical household tasks that they could not otherwise do themselves. However, paralysis in these users often limits access to traditional robot control interfaces such as joysticks or keyboards. In this work, we introduce and deploy the first system that enables a user with quadriplegia to control a mobile manipulator in their own home using bimanual high-density electromyography (HDEMG). We develop a pair of custom, fabric-integrated HDEMG forearm sleeves, worn on both arms, that capture residual neuromotor activity from clinically paralyzed degrees of freedom and support real-time gesture-based robot control. Second, by integrating vision, language, and motion planning modules, we introduce a shared autonomy framework that supports robust and user-driven teleoperation, with particular benefits for navigation-intensive tasks in home environments. Finally, to demonstrate the system in the wild, we present a twelve-day in-home user study evaluating real-time use of the wearable EMG interface for daily robot control. Together, these system components enable effective robot control for performing activities of daily living and other household tasks in a real home environment.
Bidirectional Human-Robot Communication for Physical Human-Robot Interaction
Jan 15, 2026Effective physical human-robot interaction requires systems that are not only adaptable to user preferences but also transparent about their actions. This paper introduces BRIDGE, a system for bidirectional human-robot communication in physical assistance. Our method allows users to modify a robot's planned trajectory -- position, velocity, and force -- in real time using natural language. We utilize a large language model (LLM) to interpret any trajectory modifications implied by user commands in the context of the planned motion and conversation history. Importantly, our system provides verbal feedback in response to the user, either assuring any resulting changes or posing a clarifying question. We evaluated our method in a user study with 18 older adults across three assistive tasks, comparing BRIDGE to an ablation without verbal feedback and a baseline. Results show that participants successfully used the system to modify trajectories in real time. Moreover, the bidirectional feedback led to significantly higher ratings of interactivity and transparency, demonstrating that the robot's verbal response is critical for a more intuitive user experience. Videos and code can be found on our project website: https://bidir-comm.github.io/
ORB: Operating Room Bot, Automating Operating Room Logistics through Mobile Manipulation
Sep 19, 2025
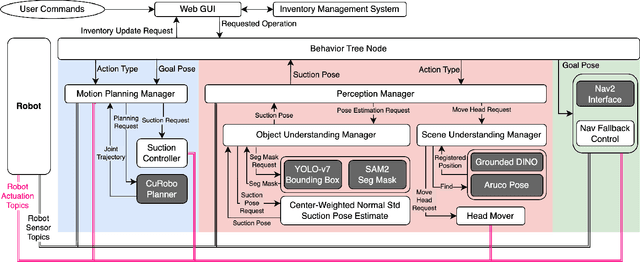
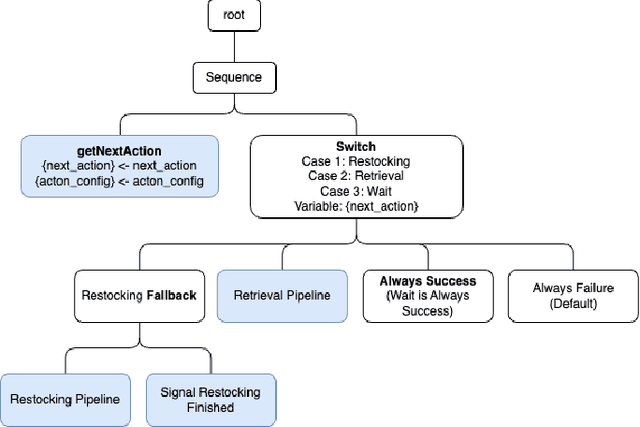
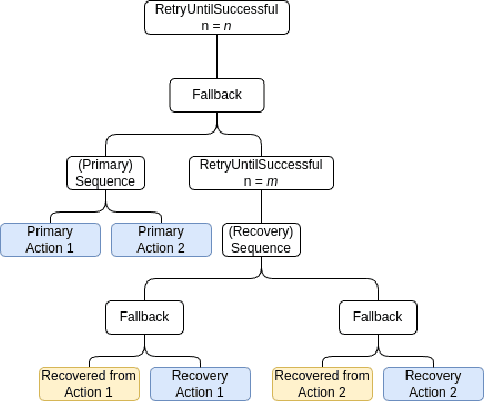
Efficiently delivering items to an ongoing surgery in a hospital operating room can be a matter of life or death. In modern hospital settings, delivery robots have successfully transported bulk items between rooms and floors. However, automating item-level operating room logistics presents unique challenges in perception, efficiency, and maintaining sterility. We propose the Operating Room Bot (ORB), a robot framework to automate logistics tasks in hospital operating rooms (OR). ORB leverages a robust, hierarchical behavior tree (BT) architecture to integrate diverse functionalities of object recognition, scene interpretation, and GPU-accelerated motion planning. The contributions of this paper include: (1) a modular software architecture facilitating robust mobile manipulation through behavior trees; (2) a novel real-time object recognition pipeline integrating YOLOv7, Segment Anything Model 2 (SAM2), and Grounded DINO; (3) the adaptation of the cuRobo parallelized trajectory optimization framework to real-time, collision-free mobile manipulation; and (4) empirical validation demonstrating an 80% success rate in OR supply retrieval and a 96% success rate in restocking operations. These contributions establish ORB as a reliable and adaptable system for autonomous OR logistics.
Force-Modulated Visual Policy for Robot-Assisted Dressing with Arm Motions
Sep 16, 2025Robot-assisted dressing has the potential to significantly improve the lives of individuals with mobility impairments. To ensure an effective and comfortable dressing experience, the robot must be able to handle challenging deformable garments, apply appropriate forces, and adapt to limb movements throughout the dressing process. Prior work often makes simplifying assumptions -- such as static human limbs during dressing -- which limits real-world applicability. In this work, we develop a robot-assisted dressing system capable of handling partial observations with visual occlusions, as well as robustly adapting to arm motions during the dressing process. Given a policy trained in simulation with partial observations, we propose a method to fine-tune it in the real world using a small amount of data and multi-modal feedback from vision and force sensing, to further improve the policy's adaptability to arm motions and enhance safety. We evaluate our method in simulation with simplified articulated human meshes and in a real world human study with 12 participants across 264 dressing trials. Our policy successfully dresses two long-sleeve everyday garments onto the participants while being adaptive to various kinds of arm motions, and greatly outperforms prior baselines in terms of task completion and user feedback. Video are available at https://dressing-motion.github.io/.
Geometric Red-Teaming for Robotic Manipulation
Sep 15, 2025Standard evaluation protocols in robotic manipulation typically assess policy performance over curated, in-distribution test sets, offering limited insight into how systems fail under plausible variation. We introduce Geometric Red-Teaming (GRT), a red-teaming framework that probes robustness through object-centric geometric perturbations, automatically generating CrashShapes -- structurally valid, user-constrained mesh deformations that trigger catastrophic failures in pre-trained manipulation policies. The method integrates a Jacobian field-based deformation model with a gradient-free, simulator-in-the-loop optimization strategy. Across insertion, articulation, and grasping tasks, GRT consistently discovers deformations that collapse policy performance, revealing brittle failure modes missed by static benchmarks. By combining task-level policy rollouts with constraint-aware shape exploration, we aim to build a general purpose framework for structured, object-centric robustness evaluation in robotic manipulation. We additionally show that fine-tuning on individual CrashShapes, a process we refer to as blue-teaming, improves task success by up to 60 percentage points on those shapes, while preserving performance on the original object, demonstrating the utility of red-teamed geometries for targeted policy refinement. Finally, we validate both red-teaming and blue-teaming results with a real robotic arm, observing that simulated CrashShapes reduce task success from 90% to as low as 22.5%, and that blue-teaming recovers performance to up to 90% on the corresponding real-world geometry -- closely matching simulation outcomes. Videos and code can be found on our project website: https://georedteam.github.io/ .
RaC: Robot Learning for Long-Horizon Tasks by Scaling Recovery and Correction
Sep 09, 2025



Modern paradigms for robot imitation train expressive policy architectures on large amounts of human demonstration data. Yet performance on contact-rich, deformable-object, and long-horizon tasks plateau far below perfect execution, even with thousands of expert demonstrations. This is due to the inefficiency of existing ``expert'' data collection procedures based on human teleoperation. To address this issue, we introduce RaC, a new phase of training on human-in-the-loop rollouts after imitation learning pre-training. In RaC, we fine-tune a robotic policy on human intervention trajectories that illustrate recovery and correction behaviors. Specifically, during a policy rollout, human operators intervene when failure appears imminent, first rewinding the robot back to a familiar, in-distribution state and then providing a corrective segment that completes the current sub-task. Training on this data composition expands the robotic skill repertoire to include retry and adaptation behaviors, which we show are crucial for boosting both efficiency and robustness on long-horizon tasks. Across three real-world bimanual control tasks: shirt hanging, airtight container lid sealing, takeout box packing, and a simulated assembly task, RaC outperforms the prior state-of-the-art using 10$\times$ less data collection time and samples. We also show that RaC enables test-time scaling: the performance of the trained RaC policy scales linearly in the number of recovery maneuvers it exhibits. Videos of the learned policy are available at https://rac-scaling-robot.github.io/.
CoRI: Synthesizing Communication of Robot Intent for Physical Human-Robot Interaction
May 26, 2025Clear communication of robot intent fosters transparency and interpretability in physical human-robot interaction (pHRI), particularly during assistive tasks involving direct human-robot contact. We introduce CoRI, a pipeline that automatically generates natural language communication of a robot's upcoming actions directly from its motion plan and visual perception. Our pipeline first processes the robot's image view to identify human poses and key environmental features. It then encodes the planned 3D spatial trajectory (including velocity and force) onto this view, visually grounding the path and its dynamics. CoRI queries a vision-language model with this visual representation to interpret the planned action within the visual context before generating concise, user-directed statements, without relying on task-specific information. Results from a user study involving robot-assisted feeding, bathing, and shaving tasks across two different robots indicate that CoRI leads to statistically significant difference in communication clarity compared to a baseline communication strategy. Specifically, CoRI effectively conveys not only the robot's high-level intentions but also crucial details about its motion and any collaborative user action needed.